Getting Started
Quickly start parsing documents with LlamaParse—whether you prefer Python, TypeScript, or using the web UI. This guide walks you through creating an API key and running your first job.
Get your API Key
🔑 Before you begin: You'll need an API key to access LlamaParse services.
Choose Your Setup
- UI
- Python
- TypeScript
- API
Using LlamaParse in the Web UI
If you're non-technical or just want to quickly sandbox LlamaParse, the web interface is the easiest way to get started.
Step-by-Step Workflow
- Go to LlamaCloud
- Choose a parsing Preset from Recommended Settings or switch to Advanced settings for a custom configuration
- Upload your document
- Click Parse and view your parsed results right in the browser
Choosing a Preset
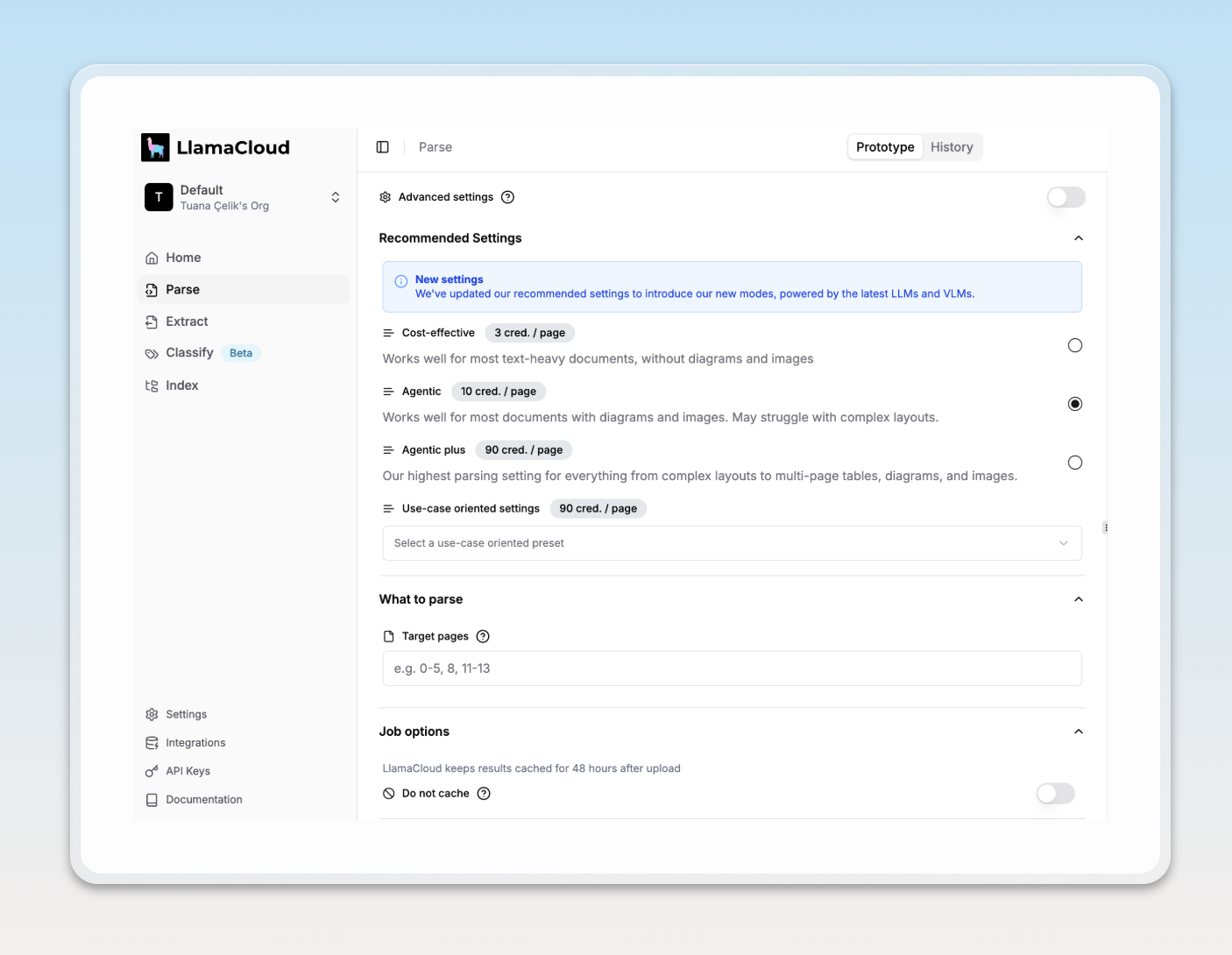
LlamaParse offers four main presets for recommended settings:
- Cost Effective – Optimized for speed and cost. Best for text-heavy documents with minimal structure.
- Agentic – The default option. Works well with documents that have images and diagrams, but may struggle with complex layouts.
- Agentic Plus – Maximum fidelity. Best for complex layouts, tables, and visual structure.
- Use-case Oriented – Which lists a set of parsing options catered to specific types of documents such as invoices, forms, technical resumes and scientific papers.
Learn more about parsing presets
Advanced Settings for Custom Modes
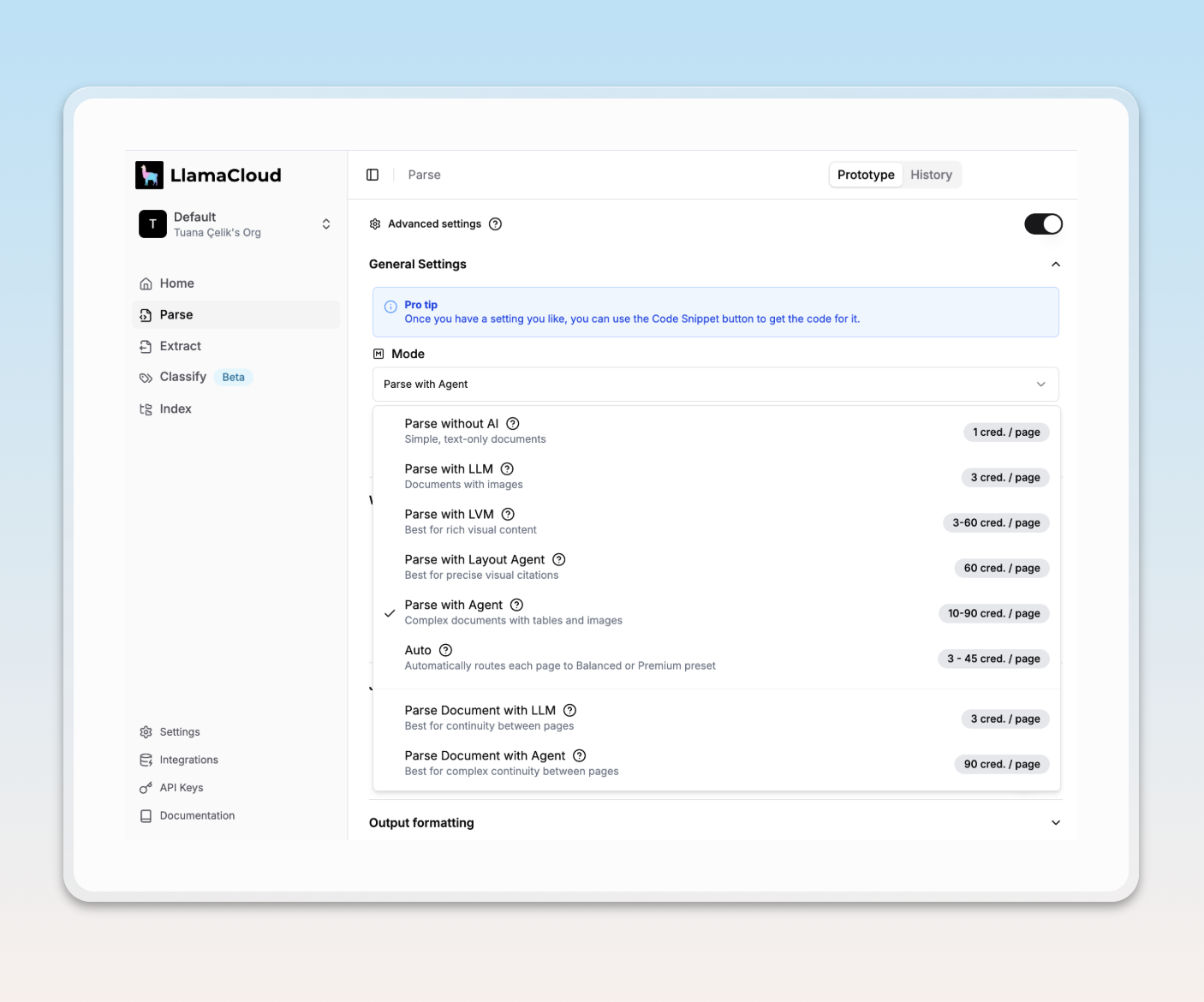
The Advanced Settings option gives you full control over how your documents are parsed. You can select from a wide range of modes including multimodal and model-specific options.
This is best suited for advanced use cases. Learn more about parsing modes
Install the package
pip install llama-cloud-services
Parse from CLI
You can parse your first PDF file using the command line interface. Use the command llama-parse [file_paths]. See the help text with llama-parse --help.
export LLAMA_CLOUD_API_KEY='llx-...'
# output as text
llama-parse my_file.pdf --result-type text --output-file output.txt
# output as markdown
llama-parse my_file.pdf --result-type markdown --output-file output.md
# output as raw json
llama-parse my_file.pdf --output-raw-json --output-file output.json
Parse in Python
You can also create simple scripts:
from llama_cloud_services import LlamaParse
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
num_workers=4, # if multiple files passed, split in `num_workers` API calls
verbose=True,
language="en", # optionally define a language, default=en
)
# sync
result = parser.parse("./my_file.pdf")
# sync batch
results = parser.parse(["./my_file1.pdf", "./my_file2.pdf"])
# async
result = await parser.aparse("./my_file.pdf")
# async batch
results = await parser.aparse(["./my_file1.pdf", "./my_file2.pdf"])
The result object is a fully typed JobResult object. You can interact with it to parse and transform various parts of the result:
# get the llama-index markdown documents
markdown_documents = result.get_markdown_documents(split_by_page=True)
# get the llama-index text documents
text_documents = result.get_text_documents(split_by_page=False)
# get the image documents
image_documents = result.get_image_documents(
include_screenshot_images=True,
include_object_images=False,
# Optional: download the images to a directory
# (default is to return the image bytes in ImageDocument objects)
image_download_dir="./images",
)
# access the raw job result
# Items will vary based on the parser configuration
for page in result.pages:
print(page.text)
print(page.md)
print(page.images)
print(page.layout)
print(page.structuredData)
That's it! Take a look at the examples below or head to the Python client docs .
Examples
Several end-to-end indexing examples can be found in the Client's examples folder:
Install the package
npm init
npm install -D typescript @types/node
LlamaParse support is built-in to LlamaIndex for TypeScript, so you'll need to install LlamaIndex.TS:
npm install llama-cloud-services dotenv
Let's create a parse.ts file and put our dependencies in it:
import {
LlamaParseReader,
// we'll add more here later
} from "llama-cloud-services";
import 'dotenv/config'
Now let's create our main function, which will load in fun facts about Canada and parse them:
async function main() {
// save the file linked above as sf_budget.pdf, or change this to match
const path = "./canada.pdf";
// set up the llamaparse reader
const reader = new LlamaParseReader({ resultType: "markdown" });
// parse the document
const documents = await reader.loadData(path);
// print the parsed document
console.log(documents)
}
main().catch(console.error);
Now run the file:
npx tsx parse.ts
Congratulations! You've parsed the file, and should see output that looks like this:
[
Document {
id_: '02f5e252-9dca-47fa-80b2-abdd902b911a',
embedding: undefined,
metadata: { file_path: './canada.pdf' },
excludedEmbedMetadataKeys: [],
excludedLlmMetadataKeys: [],
relationships: {},
text: '# Fun Facts About Canada\n' +
'\n' +
'We may be known as the Great White North, but
...etc...
You can now use this in your own TypeScript projects. Head over to the TypeScript docs to learn more about LlamaIndex in TypeScript.
Using the REST API
If you would prefer to use a raw API, the REST API lets you integrate parsing into any environment—no client required. Below are sample endpoints to help you get started.
1. Upload a file and start parsing
Send a document to the API to begin the parsing job:
curl -X 'POST' \
'https://api.cloud.llamaindex.ai/api/v1/parsing/upload' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY" \
-F 'file=@/path/to/your/file.pdf;type=application/pdf'
2. Check the status of a parsing job
Use the job_id returned from the upload step to monitor parsing progress:
curl -X 'GET' \
'https://api.cloud.llamaindex.ai/api/v1/parsing/job/<job_id>' \
-H 'accept: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY"
3. Retrieve results in Markdown
Once the job is complete, you can fetch the structured result:
curl -X 'GET' \
'https://api.cloud.llamaindex.ai/api/v1/parsing/job/<job_id>/result/markdown' \
-H 'accept: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY"
See more details in our API Reference
Example
Here is an example notebook for Raw API Usage
Resources
- See Credit Pricing and Usage
- Next steps? Check out LlamaExtract to extract structured data from unstructured documents!